
Delta Lake vs. Apache Iceberg: A Mindful Choice for Your Data Lakehouse
They are like adding a smart warehouse management system on top of your messy storage.

Imagine you have a huge digital warehouse filled with tons of boxes (your data).
At first, everything looks manageable.
You can pick up a box, see what's inside, and store it back.
But over time, the warehouse becomes chaotic:
Boxes get bigger and heavier (more data).
Some boxes change shape (schema changes).
You don’t know which version of a box you’re looking at (no time travel).
If you try moving things around, you might accidentally damage other boxes (no data consistency).
And when too many people try to move things at the same time, everything becomes a mess (no transactions).
Regular data lakes basic storage like S3, GCS, or Azure Blob are like that warehouse with no rules, no labels, and no managers.
🔵 This is where Apache Iceberg and Delta Lake come in.
They are like adding a smart warehouse management system on top of your messy storage:
📦 They keep track of every change made to your data (like a version history).
🛡️ They guarantee safety when multiple people are reading and writing data at the same time (ACID transactions).
🕰️ They allow you to travel back in time to earlier versions of your data — just like looking at an older version of a document.
🔄 They handle changes gracefully, like updating the structure of your data without breaking everything.
If you’re building or managing a data lakehouse today, chances are you’ve already heard the names Delta Lake and Apache Iceberg being thrown around.
At first glance, they seem to promise the same things:
👉 ACID transactions on your data lake
👉 Schema evolution
👉 Time travel
👉 Reliable performance at massive scale
But once you dive in, you realize they're actually quite different and choosing the right one depends a lot on your setup, your team and your long term vision.
Let's walk through a simple comparison, not the marketing slides but what you actually need to know.
🧱 Their Origins (and Why It Matters)
Delta Lake was born inside Databricks and later open sourced (though still heavily driven by Databricks’ vision).
Think: best friends with Apache Spark, deeply optimized for it.Apache Iceberg started at Netflix, faced with petabyte-scale challenges.
Later donated to the Apache Software Foundation, it now thrives under a truly open, engine agnostic philosophy.
🔵 Delta Lake: Spark-first, Databricks-powered
🧊 Iceberg: Multi-engine, community-led
What is Delta Lake?

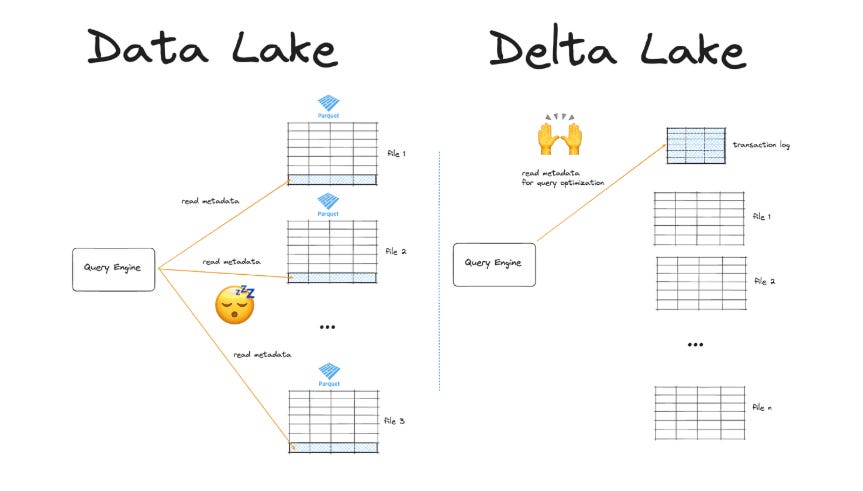
Delta Lake, initially developed by Databricks and now an open source project under the Linux Foundation, was designed to add reliability and performance layers on top of existing data lakes, primarily using the Parquet file format. Its core strength lies in bringing ACID (Atomicity, Consistency, Isolation, Durability) transactions to data lake operations, ensuring data integrity even with concurrent reads and writes. Delta Lake achieves this through a transaction log (_delta_log) that records every change made to the table. Key features include seamless integration with Apache Spark, efficient data versioning enabling time travel (querying previous states of your data) and optimizations like data compaction.
If your organization is heavily invested in the Databricks or Apache Spark ecosystem, Delta Lake often presents a natural and tightly integrated choice. It excels in scenarios requiring robust consistency for write heavy workloads and real-time streaming analytics.
# --- Setup Spark with Delta (Needs Delta installed!) ---
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.appName("DeltaLakeDemo") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()
# --- Create a simple Delta table ---
data = spark.range(0, 5)
data.write.format("delta").mode("overwrite").save("/tmp/my_delta_table")
# --- Read the table ---
df_read = spark.read.format("delta").load("/tmp/my_delta_table")
df_read.show()
# +---+
# | id|
# +---+
# | 0|
# | ...|
# | 4|
# +---+
# --- Time Travel! Read the first version (if you overwrite later) ---
# df_v0 = spark.read.format("delta").option("versionAsOf", 0).load("/tmp/my_delta_table")
# df_v0.show()What is Apache Iceberg?

Apache Iceberg originated at Netflix to address the challenges of managing massive, rapidly changing datasets in their data lake. Now governed by the Apache Software Foundation, Iceberg is designed as a truly open table format, emphasizing compatibility across various compute engines like Spark, Trino (formerly PrestoSQL), Flink, and others. Unlike Delta Lake's transaction log, Iceberg manages table state through metadata stored in manifest files, tracking individual data files within snapshots. This architecture supports features like full schema evolution (adding, dropping, renaming columns without rewriting data files), flexible partition evolution, and support for multiple file formats (Parquet, ORC, Avro). Iceberg also provides ACID guarantees and time travel capabilities.
Iceberg's strength lies in its openness and flexibility, making it a compelling option for organizations seeking to avoid vendor lock-in or needing to integrate with a diverse set of processing engines. Its robust schema and partition evolution capabilities are particularly beneficial for managing long-term datasets where structures might change over time.

-- --- Assuming you have a catalog 'demo' configured for Iceberg ---
-- --- Create a table ---
create table demo.my_iceberg_table (
id bigint,
data string,
category string
)
partitioned by (category); -- Define partitioning
-- --- Insert some data ---
insert into demo.my_iceberg_table values
(1, 'apple', 'fruit'),
(2, 'banana', 'fruit'),
(3, 'carrot', 'vegetable');
-- --- Read the data ---
select * from demo.my_iceberg_table where category = 'fruit';
-- Returns apple and banana rows
-- --- Iceberg also supports time travel (syntax might vary slightly by catalog) ---
-- select * from demo.my_iceberg_table version as of <timestamp_or_snapshot_id>;🛠️ How They Handle Your Data

Where They Fit Best
Choose Delta Lake if:
Your team is heavily invested in Apache Spark or Databricks.
You prioritize write heavy operations and need native performance.
You’re okay with being slightly tied into the Databricks ecosystem.
Choose Apache Iceberg if:
You want true engine independence: Spark, Flink, Trino, Presto... take your pick.
You expect your partitioning strategies to evolve as your data grows.
You prefer open, community driven technology over vendor driven.
Conclusion
If you're already working deep inside Databricks or Spark, Delta Lake will feel smoother.
If you're aiming for a more flexible, cloud-agnostic lakehouse or mixing multiple engines, Iceberg is your better long term bet.
Neither one is "better" universally. It all comes down to your specific use case.
Data architecture today isn't about picking "the best."
It's about picking what fits you best and being able to adapt as you grow.
I strongly suggest watching the video below:
References
Apache Iceberg Vs. Delta Lake Vs. Apache Hudi! Data Lake Storage Solutions Compared!
AWS re:Invent 2023 - Netflix’s journey to an Apache Iceberg–only data lake (NFX306)
Great engineering starts with great awareness. Be mindful, be DataConscious.
❤️ Liked this article? Make sure to push the button
💬 Community needs your voice, do you have something to add? Feel free to
🔁 Know someone that would find this helpful? Feel free to share