
The Data Career Compass (1/8): Data Engineer & Data Mesh with Konstantinos Siaterlis
Data is the backbone of modern decision making and Data Engineers are the architects behind it. Stand out by being business acumen instead of a pipeline builder. The first podcast episode is LIVE!


In this episode of DataConscious – A Mindful Approach to Analytics, we dive into the world of Data Engineering and the game-changing concept of Data Mesh. Our guest, Konstantinos Siaterlis (bsky), Senior Cloud Engineering Tech Lead at Mondelēz International and AWS Hero, shares his deep expertise in building scalable, reliable cloud infrastructure and leading Data Mesh transformations.
Below you can find his Substack publication.

Join us as we explore:
🔹 The real role of a Data Engineer – beyond the job title
🔹 Essential vs. overhyped skills in the industry
🔹 Career growth, trends, and the future of data platforms
🔹 How Data Mesh redefines data ownership and scalability
Whether you're a data leader, engineer, BI professional, or decision-maker, this episode will help you navigate the evolving landscape of modern data architectures.
🎧 Listen now & subscribe for more insights on mindful data practices!
What the role actually does (beyond the job title)
When you start as a data engineer, you expect to work with cutting edge, state of the art tools like Hadoop, Spark, and Kafka daily. Reality? Many companies still rely on legacy systems, often using drag and drop ETL tools like SSIS instead of complex coding solutions. I have seen many disappointed data engineers working on stuff that they really do not want to. But you know what? It’s always part of the job.

Core Responsibilities
Building & Maintaining Pipelines: While new pipelines are part of the job, much of the work involves migrating existing ones to newer platforms for cost savings and performance improvements FOR THE BUSINESS.
Ensuring Data Accessibility: Data engineers create structured, reliable data storage that analysts and data scientists can easily access. Often, companies provide SQL based interfaces to simplify usage.
Keeping Systems Running: Managing data infrastructure isn’t just about innovation, it’s about maintaining stability. Scaling storage, improving processing speeds and ensuring smooth data flow are critical daily tasks.
Bridging the Gap Between Raw Data and Insights: Engineers clean, organize and integrate data, making it usable for other teams. Without this foundation analytics and AI efforts WILL FAIL.
The Reality Check
Unlike data scientists, data engineers don’t get the spotlight. Their work is behind the scenes, ensuring that business decisions with data are even possible. It’s not the “sexiest job” but it’s essential. And while it may lack public/organisational recognition, the financial rewards are there! Salaries often surpass expectations as demand for skilled engineers grows.
🛠 The skills and tools required to succeed
Data engineering is an ever evolving field that requires expertise in a variety of tools and concepts. Technologies that were critical a few years ago have been replaced by more efficient solutions and modern data engineers must stay updated to remain competitive.
Skills
A strong data engineering skill set includes:
SQL & Python: SQL for querying and transforming data, Python for automation, scripting, and working with libraries like Pandas and PySpark.
Cloud Technologies: Expertise in AWS, Google Cloud, Azure, and Databricks for scalable data solutions.
Workflow Orchestration: Using tools like Apache Airflow, Prefect, Dagster to automate and manage data pipelines.
Data Modeling: Designing efficient data structures:
3rd Normal Form (3NF): Optimized for OLTP systems with structured relationships.
Data Vault: Flexible and scalable modeling for historical tracking.
One Big Table (OBT): Simplified models for analytics and reporting.
Business Acumen (my favourite): So simple as that, technical skills aren’t enough! Without business acumen, a data engineer is just a pipeline builder. Understanding company goals and industry challenges is what separates an average engineer from an indispensable one. STICK WITH ME: It's not about moving data, it’s about delivering impact. Engineers who don’t align their work with business priorities waste time and resources. Those who do? They drive revenue, streamline operations, and make data a competitive advantage. How should your manager ask for budget → and then reward you with a salary raise, if the business value is not explainable?
Tools
The modern data stack consists of:
Storage & Processing:
Databricks: Unified data analytics and AI platform, built on Apache Spark for large scale data processing.
Presto and Trino: Powerful distributed SQL engines designed for querying massive datasets across multiple sources. Originally built at Facebook, Presto was later forked into Trino for improved performance and scalability.
Apache Iceberg & Delta Lake: Ensuring schema evolution, ACID transactions and efficient lakehouse management.
BigQuery, Snowflake, Redshift: Scalable cloud data warehouses.
Data Ingestion & Integration:
Airbyte & Fivetran: Low code ELT tools for seamless data movement.
Kafka & Debezium: Real time data streaming and Change Data Capture (CDC) solutions.
Data Transformation:
dbt (Data Build Tool): Managing and defining analytics ready datasets.
Data Engineering Concepts
Key concepts for handling and structuring data effectively:
Change Data Capture (CDC): Tracking and processing real time database changes.
Slowly Changing Dimensions (SCD): Managing historical data changes for accurate reporting. SCD is like keeping a historical record of the data, while CDC is like getting real time updates on any changes made to that data.
ETL vs. ELT: Traditional ETL (Extract, Transform, Load) vs. modern ELT (Extract, Load, Transform) for scalability.
Batch vs. Streaming Processing: Choosing between scheduled batch jobs and real time event driven pipelines.
Lakehouse Architecture: Combining the best of data lakes and warehouses with tools like Databricks & Delta Lake.

📈 Career growth opportunities and salary expectations
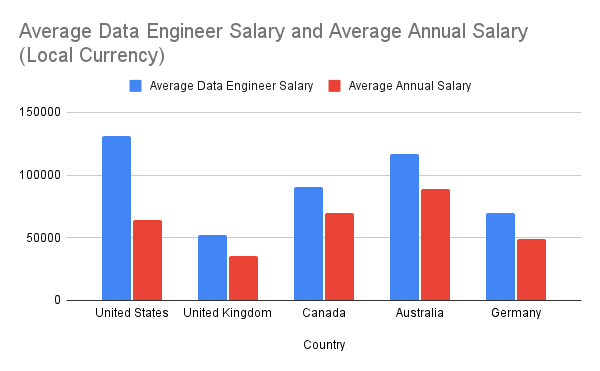
Data is the new gold of the 21st century (sic). Some of the largest companies in the world process terabytes of information daily and data engineering has become one of the highest demand jobs globally. A quick search on LinkedIn reveals thousands of job postings for data engineers, with an average salary of $130,000 per year in the U.S. The demand is immense, yet the market remains relatively niche.
The Power of Now in Career Growth
Success thrives in the present moment. Every opportunity whether from friends, clients, or unexpected encounters exists now and the key is to seize it without hesitation. When a chance to contribute arises, say yes without overanalyzing. The present moment is where momentum is built when things are working, don’t pause to overthink. Lean into the flow, embrace the now and let it carry you forward.
Laying the Foundation: Building a Strong Data Career Portfolio
To truly capitalize on opportunities, it’s essential to establish a solid foundation:
Master the fundamentals: Python, SQL, and command line proficiency are the backbone of data engineering.
Say yes to skill-building opportunities: Engage in projects that push your limits and broaden your expertise.
Reduce risk: Expand your network and diversify your skill set.
Many people feel overwhelmed when starting their data engineering journey because of the sheer number of tools and buzzwords Spark, Hadoop, Hive, Airflow and so on. Unlike software engineering, where roles are well-defined, data engineering is more ambiguous.
However, a quick glance at job descriptions on LinkedIn reveals a pattern:
Expertise in relational SQL
Proficiency in Python
Experience with workflow scheduling tools like Apache Airflow
These foundational skills are critical for getting started. Once you gain confidence in Python, SQL, and command line (CLI) operations, you’ll be ready to tackle data storage, orchestration, and workflow automation which are the key components of modern data systems.
It’s important to focus on concepts rather than tools. Technologies evolve rapidly by the time you master one, a newer version will emerge. Instead, learn core principles like distributed computing and scalable data architectures.
The Mindset for Long-Term Success
Success in data engineering or any field demands practice through projects and building a strong portfolio. The hardest part of starting out is feeling lost due to the overwhelming number of resources. Stick to one high quality resource and master it before moving on.
Instead of reading documentation endlessly, start building. Experiment, make mistakes, and refine your understanding through hands on projects.
Take calculated risks, optimize for long term value, and continuously seek ways to own your career trajectory. The best opportunities come not from job applications but from the things you create and share with the world.
🔁 How to transition into the role effectively
🔹 Junior Engineers → Start with SQL (it's everywhere), get comfortable with Python, and understand ETL vs. ELT. Learn how to work with JSON, XML, YAML, and the basics of data modeling (star schema, Data Vault, One Big Table, 3NF etc).
Oh, and don’t forget Git…you’ll be using it a lot!
🔹 Senior Engineers → Master data modeling, CDC, data streaming, and infrastructure. You should be able to navigate CI/CD, automation, and cloud platforms effortlessly. Most importantly, you’re no longer just executing, you’re making key technical decisions and mentoring others.
🔹 Lead Engineers → You’re setting the architecture vision, ensuring security & performance, and influencing the entire org’s data strategy. You’re not just coding anymore, you’re leading, guiding, and making sure everything scales and breaks rarely.
Remember: You don’t need to know it all at once. Stay curious, stay adaptable, and keep learning.

🎙 What the Data Pros Say
Beyond the technical breakdowns, you’ll hear from experienced professionals in each role. Through our ‘What the Data Pros Say’ section, we’ll bring you firsthand insights from people actively working in the field. Thanks to everyone for contributing guys :)

Like many, I initially jumped on the data science hype train, eager to build cool machine learning models. It felt like being a wizard, conjuring insights from raw data! But I quickly hit a wall – my magical models were failing because the data was a mess. It was like trying to bake a cake with sand instead of flour. That’s when I discovered the real magic: data engineering. It’s not as flashy, sure, but it’s the bedrock of everything. Data engineering is like building the solid foundation and sturdy frame of a house before you start decorating with fancy (data science) furniture. Without it, the whole thing collapses. It’s the unsung hero, making sure the data is clean, reliable, and ready for its close-up.

My journey into data engineering began in physics, where I fell in love with solving problems using data and programming. From analyzing data produced by experiments to building simulations in C. That passion led me here. Here are a few thing I learned as a data engineer, the past years:
Master the basics: They’re timeless and most are technology-agnostic.
Know your tools: They’re your leverage in building efficient systems. This includes everything from the text editor you use to the last tool in your current stack.
Embrace change: This field evolves fast, and loving to learn is non-negotiable.
Learn to communicate with non-technical people: Translating business needs into data solutions is key. Let me tell you a secret, sometimes the best solution might not even require a technical implementation.
Share your knowledge: Teaching others, documenting processes, and fostering a culture of learning can amplify your impact far beyond your own work.
Remember, “If you want to go fast, go alone. If you want to go far, go together.” Stay curious, keep learning, and enjoy the journey. The data world is full of opportunities and challenges!

I came into data engineering through the backdoor, studying AI I quickly realized that no matter how powerful an algorithm is, it’s useless if the data feeding it is unreliable, messy, or slow to arrive. Without clean, reliable, and well-structured data, even the best analysts and data scientists are stuck fighting fires instead of driving impact. That’s where data engineering comes in. It’s not just about moving data from point A to point B but about enabling teams to trust their data, make better decisions, and focus on solving real problems. Whether it’s building scalable cloud pipelines or ensuring smooth data flows across an organization, data engineering is what turns raw information into real business value. And that’s what makes it so rewarding
Long story short:
It’s not as flashy, sure, but it’s the bedrock of everything.
Translating business needs into data solutions is key.
It’s not just about moving data from point A to point B but about enabling teams to trust their data, make better decisions, and focus on solving real problems.
In a nutshell…

Additional material:
https://www.datamesh-architecture.com/
https://www.datamesh-governance.com/
Great engineering starts with great awareness. Be mindful, be DataConscious.
❤️ Liked this article? Make sure to push the button
💬 Community needs your voice, do you have something to add? Feel free to
🔁 Know someone that would find this helpful? Feel free to share